
Authors: Mridul Vij and Abhinav Singh
Why Leverage Dynamic Tables?
Dynamic tables serve as fundamental building blocks in the declarative data pipeline. They offer a cost-effective and automated approach to streamline the data engineering process in Snowflake, simplifying transformation tasks. Using dynamic tables eliminates the need to define and manage a series of transformation tasks with dependencies. Instead, you can focus on writing the end state of transformation logic, leaving Snowflake to handle the complexities of pipeline management.
In a dynamic table, you can materialize the output of a query that you specify. Unlike the conventional approach of creating a separate target table and writing code to transform and store data, dynamic tables allow you to define the transformation logic or SQL statement directly within the table definition. The query’s result will be stored in the table, and an automatic process will periodically refresh or materialize the results based on the schedule defined in the table definition. This automated process simplifies data transformation and keeps the table updated with the latest information.
Dynamic Table Syntax:
CREATE [ OR REPLACE ] DYNAMIC TABLE <name>
TARGET_LAG = { ‘<num> { seconds | minutes | hours | days }’ | DOWNSTREAM }
WAREHOUSE = <warehouse_name>
AS <query>
Example of Dynamic Tables:
CREATE OR REPLACE DYNAMIC TABLE myDynamicTable
TARGET_LAG = ‘2 minutes’
WAREHOUSE = SnowflakeWarehouse
AS
SELECT DISTINCT customer_id, customer_name FROM SnowflakeTable;
In the above example:
- The dynamic table materializes the results of the defined SQL and stores the distinct ‘customer_id’ and ‘customer_name’ columns from the ‘SnowflakeTable’
- The target lag of 2 minutes ensures that the data in the dynamic table should always be within the last 2 minutes compared to the data in the ‘SnowflakeTable’, which means if a query runs for 5 seconds then the scheduled refresh will run at 1 minute 55 seconds.
- For the automated refresh process, the dynamic table utilizes the ‘SnowflakeWarehouse’ warehouse to perform the refresh.
SHOW DYNAMIC TABLES:
Warehouse is not required to execute the command. To view a dynamic table, the user must have a role with MONITOR privilege on the table.
SHOW DYNAMIC TABLES LIKE ‘product_%’ IN SCHEMA mydb.myschema;

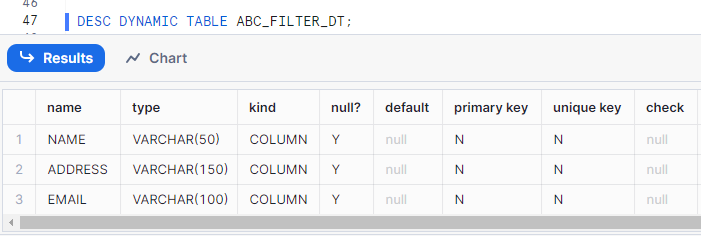
DESCRIBE DYNAMIC TABLES
DESC[RIBE] DYNAMIC TABLE <name>;
ALTER DYNAMIC TABLES
To make changes to a dynamic table, the user must be using a role with OPERATE privilege granted on the dynamic table.
ALTER DYNAMIC TABLE <name> SET
[ TARGET_LAG = { ‘<num> { seconds | minutes | hours | days }’ | DOWNSTREAM } ]
[ WAREHOUSE = <warehouse_name> ]

DROP DYNAMIC TABLES
Dropping a dynamic table requires the user to be using a role with OWNERSHIP privilege on the table.
DROP DYNAMIC TABLE <name>;
Mechanics of a Dynamic Table
When you create a dynamic table, you define a query that transforms data from one or more base or dynamic tables. An automated refresh process then regularly executes this query, updating the dynamic table with any changes made to the base tables.
The automated process calculates the modifications made to the base tables and incorporates these changes into the dynamic table. To accomplish this task, the process utilizes compute resources from the warehouse linked to the dynamic table.
When setting up a dynamic table, you define a desired data “freshness” or target lag. This indicates how up-to-date the data in the dynamic table should be compared to updates in the base table. For instance, you can specify that the dynamic table should not be more than 5 minutes behind the updates in the base table. The automated process then schedules refreshes accordingly to ensure that the data in the dynamic table remains within the specified target freshness (e.g., within 5 minutes of the base table updates).
When data freshness is not a critical factor, it is possible to opt for a longer target freshness time, which can help in reducing costs. For instance, if the data in the target table only needs to be within 1 hour of updates to the base tables, one can specify a target freshness of 1 hour instead of the previous 5 minutes, leading to potential cost savings.

Image source: Snowflake docs
When to Use Dynamic Tables?
Dynamic tables in Snowflake enable a wide range of real-time data processing and analytics capabilities across various industry domains. By leveraging streams and tasks, organizations can maintain up-to-date views of their data, allowing for timely and informed decision-making.
Sectors in which it is used are
- Financial Services
- Healthcare
- Retail
- Manufacturing
- Logistics
In your data pipeline, you have several options for transforming data, such as using streams and tasks, CTAS (Create Table As Select), custom solutions, and dynamic tables. Dynamic tables are just one of the available approaches for data transformation.
We will discuss the differences between several data transformation approaches using dynamic tables in this document, as well as which is best for you.
Dynamic tables are best used for the following cases:
- Avoid writing code to handle data dependencies and manage data refresh.
- Prefer a simple solution and avoid the complexity of streams and tasks.
- Don’t require fine-grained control over the refresh schedule.
- Need to materialize the results of a query involving multiple base tables.
- Do not use unsupported dynamic query constructs like stored procedures, non-deterministic functions (not listed in “Non-Deterministic Functions Supported in Dynamic Tables”), or external functions.
- Use dynamic tables to implement slowly changing dimensions.
- Dynamic tables can handle complex queries well.
- Multiple joins, partitions, and unions can be used in a single table, this will make the query complex and hence will result in more cost.
Limitations
- Unequal joins (i.e. joins having less than, greater than, or not equal to conditions) will lead to full refresh.
- The data cannot be updated manually, the dynamic table behaves like views and is immutable.
- Change in definition needs recreation of the dynamic table.
- A single account can hold a maximum of 4000 dynamic tables.
- In a dynamic table, You can’t query more than 100 tables and 100 dynamic tables.
- You can’t truncate data from a dynamic table.
- You can’t create a transient or temporary dynamic table.
- When you use a dynamic table to ingest shared data, the query can’t select from a shared dynamic table or a shared secure view that references an upstream dynamic table.
- You can’t use secondary roles with dynamic tables because dynamic table refreshes act as their owner role.
The following constructs are not currently supported in the query for a dynamic table:
- External functions.
- Functions that rely on CURRENT_USER. Dynamic table refreshes act as their owner role with a special SYSTEM user.
- Sources that include directory tables, Iceberg tables, external tables, streams, and materialized views.
- Views on dynamic tables or other unsupported objects.
- User-defined functions (UDFs and UDTFs) written in SQL.
- UNPIVOT constructs are not supported in dynamic table incremental or full refresh.
The following cross-feature interactions are not supported:
- Enabling search optimization on a dynamic table.
- Using the query acceleration service (QAS) for dynamic table refreshes.
- The following limitations apply to cross-feature interactions:
Dynamic tables and base tables that are in different failover groups cause replication to fail.
Dynamic tables don’t currently support the incremental refresh of some constructs, operators, and functions as mentioned below:
- PIVOT.
- UNPIVOT.
- Set Operators:
- UNION, MINUS, EXCEPT, INTERSECT.
- The following use of UNION [ ALL ]:
- UNION ALL of a table and itself or a clone of itself.
- UNION ALL of two GROUP BYs.
- Lateral Join.
- The following outer join (left, right, or full) patterns:
- Outer joins where both sides are the same table.
- Outer joins where both sides are a subquery with GROUP BY clauses.
- Outer joins with non-equality predicates.
- The following uses of window functions:
- Multiple window functions in the same SELECT block with non-identical PARTITION BY clauses.
- Using the window functions PERCENT_RANK, DENSE_RANK, RANK with sliding windows.
- Using ANY since it’s a non-deterministic function.
- User-defined tabular functions (UDTF).
Challenges:
- Finding workarounds for unequal joins and functions that will lead to full refresh.
- Dynamic table will reduce the hops unlike stream tasks SPs but the cost may be on the higher side.
Additional limitations with incremental refresh:
- User-defined functions (UDF): Replacing an IMMUTABLE UDF while it’s in use by a dynamic table that uses incremental refresh might result in unexpected behavior in that table. VOLATILE UDFs are not supported with incremental refresh.
- Masking and row access policies: Dynamic tables don’t currently support incremental refresh for sources with masking or row access policies. If the underlying table is protected by a policy, the dynamic table uses full refresh.
- Replication: Replicated dynamic tables with incremental refresh reinitialize after failover before they can resume incremental refresh.
- Cloning: In certain cases, cloned incremental dynamic tables might need to reinitialize on their first refresh after being created.
New enhancements as of April 29th, 2024:
- Dynamic Tables are now generally available.
- Dynamic tables can now be shared across regions and clouds using Snowflake’s sharing and collaboration features. This makes it easy to share clean, enriched, and transformed data products with consumers in your organization, partner organizations, or the broader data cloud community, ensuring they stay updated according to your specified cadence.
- Dynamic tables now support high availability through Snowflake’s replication infrastructure i.e. supported with Snowflake’s disaster recovery solutions.
- New functionality was added for better observability via Snowsight and programmatic interfaces i.e. new account-level views, visibility into warehouse consumption, improved graph and refresh history, and the ability to suspend and resume refreshes. Observability functions now include new account usage views, extended retention of information schema functions, and added support for consistent metadata across Snowflake observability interfaces.
- Added support for clustering, transient dynamic tables, and governance policies (on sources of dynamic tables and dynamic tables themselves), allowing you to benefit from the best features of the Snowflake Data Cloud.
- You can now create four times more dynamic tables in your account, and ten times more dynamic table sources feeding into another dynamic table. There are no longer any limits on the depth of a directed acyclic graph (DAG) that you can create.
- Dynamic tables now automatically evolve to absorb new columns from base tables without needing to rebuild the dynamic table when new columns are added, as long as the changes do not affect the schema of the dynamic table.
- Dynamic can now be used in managed accessed schema.
Cost of Dynamic Tables
Snowflake dynamic tables, leveraging streams and tasks, can incur various costs that developers and organizations need to consider. There are various costs involved as explained below:
Compute cost
There are two compute costs associated with dynamic tables: virtual warehouses and Cloud
- Dynamic tables require virtual warehouses to refresh – that is, run queries against base objects for both scheduled and manual refreshes.
- Warehouses only consume credits for the duration of the refresh.
Storage cost
Storage is needed for dynamic tables to keep the materialized results. Time travel, fail-safe storage, and cloning capability may result in additional storage costs, just like with ordinary tables.
- Time Travel and fail-safe storage: Frequent refreshes can increase the buildup of Time Travel data, which adds to your overall storage usage. Based on the configured fail-safe period, additional storage charges might apply.
- Additional storage for incremental refresh operations: Dynamic tables keep an extra internal metadata column to identify each row in the table for incremental refresh operations. Internal row identifiers raise storage costs linearly with the number of rows in the table and use a fixed amount of storage each row
Target Lag Cost
- Dynamic table refreshes are driven by the configured target lag (Min 1 min).
- Dynamic table pipelines with lower target lag refresh more often and therefore incur higher compute costs.
- More frequent task scheduling results in higher compute costs. Developers need to balance the frequency of task execution with cost considerations.
Additional Cost
- Cross-Region Transfers: If data is transferred across different Snowflake regions or cloud providers, additional network transfer costs may apply.’
- Monitoring Tools: Using Snowflake’s monitoring and alerting tools to track the performance and status of dynamic tables, streams, and tasks may involve additional costs.
- Maintenance Operations: Regular maintenance tasks, such as vacuuming streams or optimizing storage, consume compute resources and contribute to costs.
- Security Features: Enabling advanced security features like data encryption, access controls, and auditing may have associated costs.
- Testing and Validation: Comprehensive testing and validation of dynamic table setups can lead to increased resource usage during the development phase.
Using a basic query (which takes 500 ms to execute) on a small dataset, with Target_Lag set to 2 minutes, the dynamic table will take 1 credit in total in an hour. This cost is dependent on various factors as well, such as scheduling multiple dynamic tables concurrently, which will be more efficient than scheduling just one, setting a target_lag to some other interval, etc.
Cost Management Strategies
To manage and optimize costs associated with Snowflake dynamic tables, consider the following strategies:
- Optimize Target Lag: Schedule dynamic tables to refresh to run at optimal frequencies to balance real-time processing needs with cost considerations.
- Use Appropriate Warehouse Sizes: Select the appropriate warehouse size for tasks, and utilize auto-scaling and auto-suspend features to minimize idle compute costs.
- Efficient Data Processing: Optimize SQL queries and processing logic to reduce compute resource consumption.
- Monitor and Adjust: Continuously monitor resource usage and adjust configurations as needed to avoid unnecessary costs.
- Retention Policies: Implement data retention policies to manage the storage costs of stream metadata and intermediate data.
- Utilize Cost Controls: Set up budgets and alerts in Snowflake to monitor and control spending on computing and storage resources.
- Use downstream lag: Downstream lag indicates that the dynamic table should refresh when other dependent dynamic tables require refreshing. You should use downstream lag as a best practice because of its ease of use and cost-effectiveness.
- Use transient dynamic tables to reduce storage cost: Transient dynamic tables maintain data reliably over time and support Time Travel within the data retention period, but don’t retain data beyond the fail-safe period. By default, dynamic table data is retained for 7 days in fail-safe storage.
Streams on Dynamic Tables
Streams can be created on dynamic tables in a manner similar to how streams are applied to conventional tables. However, it’s important to take note of the subsequent constraints:
REFRESH: Streams can be established on dynamic tables, irrespective of whether these tables undergo incremental or complete refresh. It’s requisite to remember that streams generate event sets when modifications occur in the underlying table. In the event of a dynamic table refresh, every refreshed row will yield a stream event. In the case of a full table refresh, a stream event or row will be created for each individual row within the dynamic table.
Stream type: Only standard streams are supported by Dynamic tables. Refer to Types of Streams for more information.
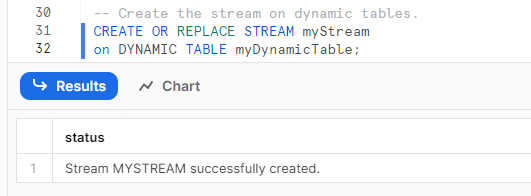
Create the stream.
CREATE OR REPLACE STREAM SnowflakeStream on DYNAMIC TABLE DT;
Dynamic Table vs Streams & Tasks
- Dynamic tables employ a ‘declarative approach’ where you define a query to specify the desired result. The data is then fetched and transformed from the base tables involved in the query.
On the other hand, Tasks adopt an ‘imperative approach’, where you write procedural code to perform data transformations directly from the base tables.
- In Dynamic Table, the automated refresh process establishes the refresh schedule, ensuring the dynamic table meets the desired data freshness level.
Whereas in Task, you can schedule the code execution to transform the data.
- While the SELECT statement for a dynamic table can involve joins, aggregations, window functions, and other SQL constructs, it cannot include calls to stored procedures and tasks. Additionally, currently, it cannot include calls to User-Defined Functions (UDFs) and external functions.
The procedural code used in Stream and Task is allowed to include calls to non-deterministic code, stored procedures, and other tasks. It can also contain calls to User-Defined Functions (UDFs) and external functions.
- An automated refresh process carries out incremental refreshes of dynamic tables at regular intervals. The schedule for these refreshes is determined by the specified target “freshness” of the data.
Tasks have the ability to leverage streams to perform incremental data refreshes on target tables. You can conveniently schedule these tasks to execute at regular intervals.

Image source: Snowflake docs
Dynamic Table vs Materialized Views
- Dynamic tables are specifically intended for transforming streaming data within a data pipeline.Even though dynamic tables can improve query performance, Snowflake’s query optimizer doesn’t automatically rewrite queries to take advantage of dynamic tables. To include a dynamic table in a query, you must explicitly specify it.
On the other hand, materialized views are designed to seamlessly enhance query performance. When querying the base table, Snowflake’s query optimizer can automatically rewrite the query to access the materialized view instead, transparently improving performance.
- A dynamic table allows you to build it upon a complex query, supporting joins and unions for data transformation.
In contrast, materialized views are limited to using a single base table and cannot be built on complex queries involving joins or nested views.
- Regarding data freshness, a dynamic table reflects data up to the target_lag time specified.
On the other hand, data accessed through materialized views is always current. If any Data Manipulation Language (DML) operation modifies the base table, Snowflake updates the materialized view accordingly, ensuring the data remains up-to-date.
Consideration While Working With Dynamic Tables
1. Complexity in Setup and Management
- Configuration Overhead: Setting up dynamic tables requires careful configuration and an understanding of their interactions.
- Dependency Management: Ensuring the correct order of execution for dependent tasks can be complex, especially in workflows with multiple dependencies.
2. Latency Considerations
- Processing Latency: Although dynamic tables aim to process data in real-time, there might be some inherent latency depending on the complexity of the processing logic and the frequency of task execution.
- Task Scheduling Granularity: Tasks in Snowflake can be scheduled with a minimum granularity of one minute, which may not be sufficient for ultra-low latency requirements.
3. Cost Implications
- Resource Consumption: Continuous processing can lead to increased compute resource usage and, consequently, higher costs.
- Task Billing: Each task execution incurs costs, which can accumulate rapidly if tasks are scheduled frequently or have complex processing logic.
4. Data Consistency and Concurrency
- Concurrent Modifications: Handling concurrent modifications to the same data can be challenging, and developers need to ensure that their processing logic accounts for potential conflicts.
5. Limitations in SQL Support
- SQL Functionality: Not all SQL functions and operations are supported within tasks. Developers need to verify that their required SQL operations are compatible with Snowflake’s task framework.
- Stored Procedures: While stored procedures can be used in tasks, there might be limitations on the operations that can be performed within them, especially concerning external integrations.
6. Debugging and Monitoring Challenges
- Troubleshooting: Debugging issues in a dynamic table setup can be more challenging due to the asynchronous nature of task execution and the complexity of dependency chains.
- Monitoring: Comprehensive monitoring and alerting mechanisms are required to track the status and performance of tasks and streams. Snowflake provides some tools for this, but additional monitoring infrastructure might be necessary.
7. Schema Changes
- Schema Evolution: Handling schema changes in source tables requires careful planning. Streams and tasks need to be adjusted to accommodate schema changes without interrupting data processing.
- Backward Compatibility: Developers need to ensure backward compatibility when making schema changes to avoid breaking existing processing logic.
8. Data Retention and Recovery
- Recovery Mechanisms: In case of failures, recovery mechanisms need to be in place to reprocess or backfill missed data, which can add to the complexity of the setup.
9. Integration with External Systems
- Data Ingestion: Integrating Snowflake dynamic tables with external data sources requires additional tools or services, and the setup might not be straightforward.
- Exporting Processed Data: Similarly, exporting processed data from Snowflake to other systems can involve additional steps and tools.
10. Learning Curve
- Learning Overhead: Developers need to invest time in learning the concepts and best practices of using streams, tasks, and dynamic tables in Snowflake.
- Documentation and Community Support: While Snowflake has good documentation, the relatively newer feature of dynamic tables might have limited community support and examples.
Conclusion
Dynamic tables in Snowflake represent a remarkable advancement in data management and analytics. Their ability to adapt and evolve in real-time based on changing data needs empowers businesses to make more informed decisions. With features like automatic scaling, improved performance, and simplified maintenance, dynamic tables offer a streamlined approach to handling data growth and variability.
While Snowflake dynamic tables provide robust real-time data processing capabilities, developers must navigate several limitations related to complexity, cost, latency, data consistency, SQL support, debugging, schema changes, data retention, integration, and the learning curve. Proper planning and best practices can mitigate many of these challenges, enabling effective use of dynamic tables in real-time analytics workflows.
References:
- Dynamic Tables | Snowflake Documentation
- Understanding Dynamic Table Refresh | Snowflake Documentation
- Creating Dynamic Tables | Snowflake Documentation
- Dynamic Tables Compared to Streams & Tasks, and Materialized Views | Snowflake Documentation





