
By Srutimala Deka
Co-Authors: Puneet Lakhanpal, Vivek Kanna Jayaprakash
Ever wondered how brands offer tailored solutions to each of their customers at lightning speed?
Introduction
We took the example of a credit card recommendation solution that caters to each user on the website — all at once, using Snowflake!
We built a custom recommendation model and deployed it in the same environment where the data resides, with the provision to use the model within any custom website.
In this blog we aim to:
- Provide insights into deploying and optimizing ML models for low latency inference on Snowpark Container Services (SPCS), addressing a critical need for many businesses.
- Outline architectural patterns and optimizations such as leveraging specific technical configurations to achieve desired performance metrics.
- Showcase a POC that achieved an impressive inference of 0.17 seconds latency for 200 concurrent users.
Problem Statement
When a customer visits a credit card website or mobile application, a delay of even a few seconds in receiving a personalized recommendation can lead to:
- Missed Opportunities: A delayed recommendation means a lost chance to engage the customer at their peak interest. The relevancy and impact of a recommendation diminish rapidly with time.
- Negative Brand Image: A clunky, slow experience can erode trust and negatively impact brand perception, making it harder to build long-term customer loyalty.
Our objective in this series of experiments is to directly address the critical pain point of building and deploying a credit card recommendation model within Snowflake such that its inference latency is consistently 1 second or less for up to 200 concurrent users.
Solution Design and its Components
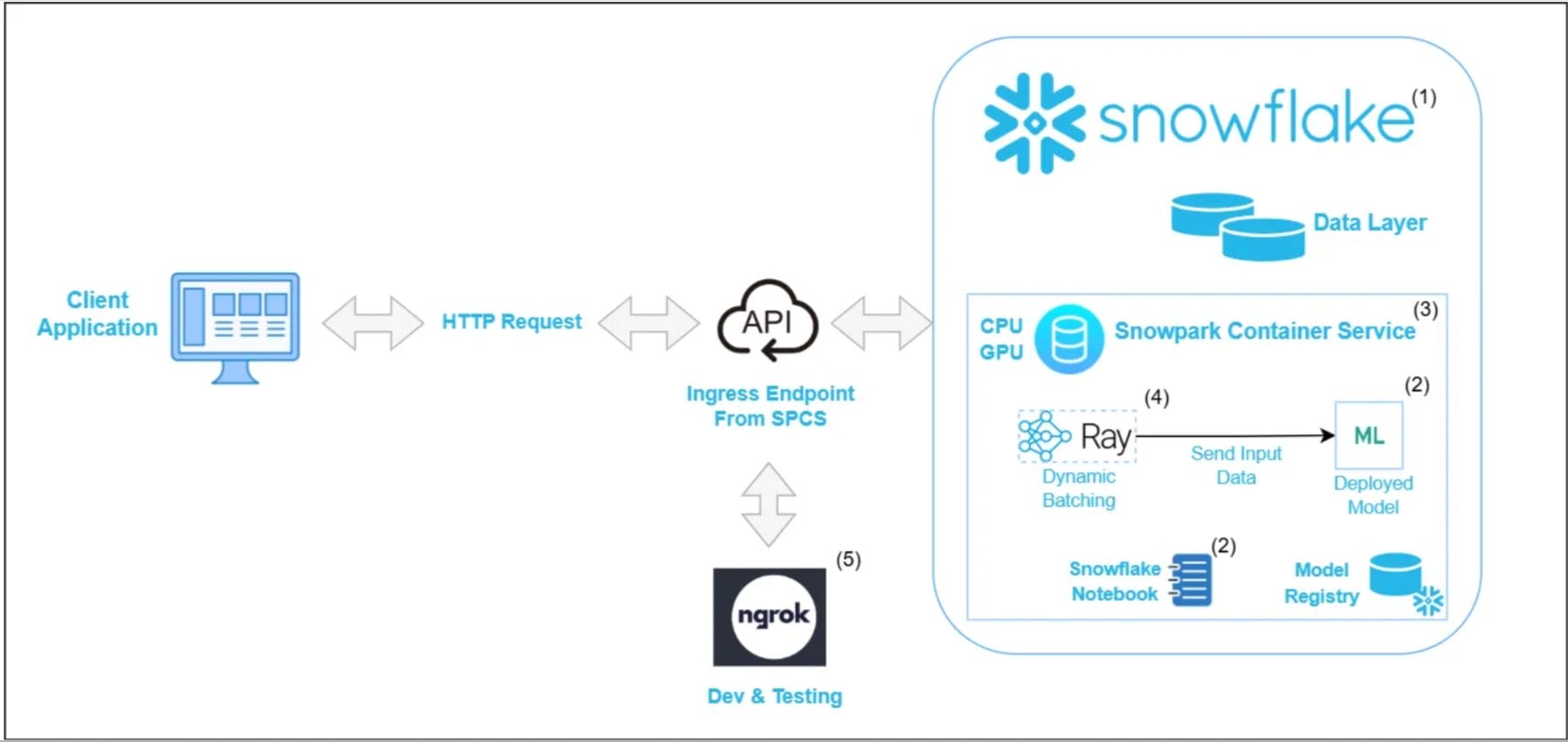
The following design components compose the final solution:
- Snowflake: The foundational platform where the credit card data resides. By having the credit card data directly within Snowflake, we eliminate the need for costly and time-consuming data movement to external platforms for model training and inference. This ensures data residency, simplifies governance and compliance, and significantly reduces the security risks associated with moving sensitive financial data. Its robust data warehousing capabilities provide a reliable and scalable source for our recommendation model.
- Machine Learning Model (Python with numpy, sklearn, Snowflake Python Notebooks): The core intelligence generating credit card recommendations. An LTR (Learning to Rank) model was developed using standard Python libraries. Building the model within Snowflake Python Notebooks ensures that data and development happen in the same secure environment, preventing data egress.
- Snowpark Container Services (SPCS): The robust deployment and serving environment for our model within Snowflake. SPCS is a fully managed service within Snowflake that allows users to deploy and run containerized applications, including custom machine learning models, directly within the Snowflake environment. SPCS is critical for achieving low inference latency by providing a dedicated, scalable environment for model serving. Its ability to leverage CPU and GPU compute pools allows us to select the optimal hardware for our LTR model, while multiple compute nodes enable parallel processing of inference requests, significantly boosting throughput and reducing individual request latency.
- Ray Serve: A framework for highly scalable and performant model serving. The key benefit of Ray Serve in our scenario is its dynamic request batching. For an LTR model, individual inference requests might be small. Ray Serve efficiently groups multiple incoming requests into larger batches, which can then be processed much more efficiently by the underlying hardware (CPU/GPU). This maximizes compute utilization and significantly reduces the per-request latency for our credit card recommendations, contributing directly to the 1-second target.
- Ngrok: A secure tunneling service for exposing local services to the internet. Ngrok played a crucial role during the experimentation and testing phase to rapidly expose our model running in various environments (like Google Colab or a local Ray cluster) for external access and latency testing.
Experimentations Conducted with Snowflake SPCS
The goal to a sub-second inference latency for credit card recommendations involved a series of experiments designed to uncover optimal configurations within Snowpark Container Services (SPCS).
The results, summarized below, reveal an interesting interplay of compute resources, architectural choices, and optimizations –
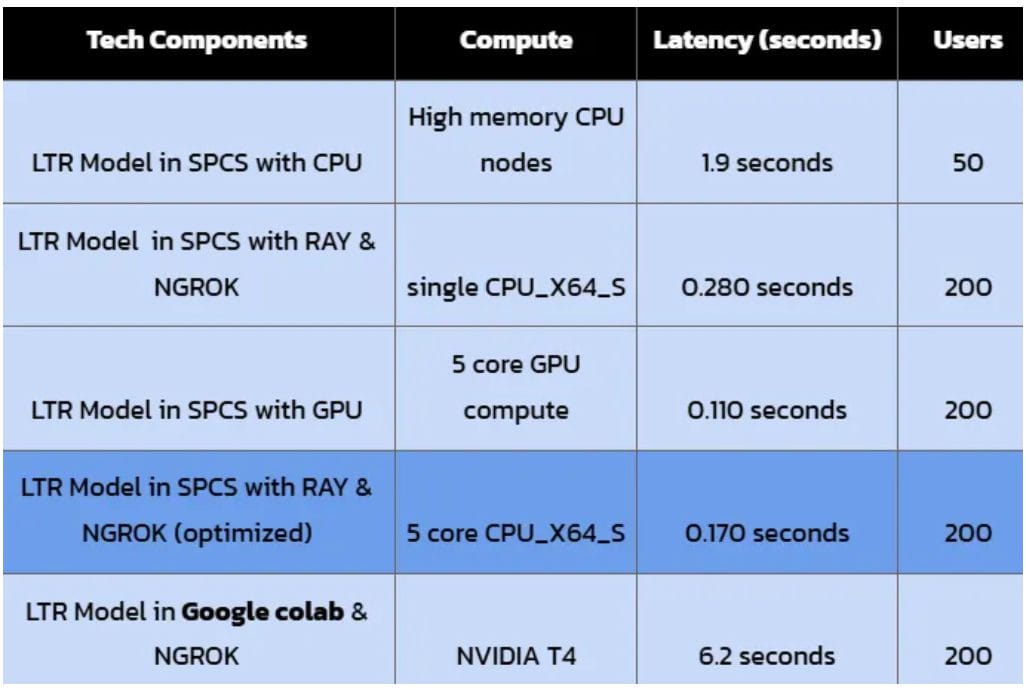
Initial Baseline and Bottleneck
Our first attempt, deploying the LTR Model in SPCS on High memory CPU nodes, yielded a latency of 1.9 seconds for 50 users. The single instance of CPU nodes wasn’t enough; further optimization of compute and serving strategy was required to hit our sub-second target.
Optimization with Ngrok and CPU_X64_S Compute
A significant improvement occurred when we deployed the LTR Model in SPCS with Ray and Ngrok on a single CPU_X64_S instance. The latency plummeted to a remarkable 0.280 seconds for 200 users. This can be attributed to the following:
- Ray’s Efficiency with Dynamic Batching: This result strongly validates the power of Ray Serve’s dynamic batching. By efficiently grouping multiple inference requests, the CPU_X64_S instance, though seemingly smaller than “high memory CPU nodes” was able to process requests much more effectively.
- Ngrok’s Role in Testing: While Ngrok wouldn’t be part of a production architecture, its presence here was crucial for simulating real-world client requests and measuring true end-to-end latency from an external perspective. It provided a quick and easy way to expose our SPCS service for external testing without complex network configurations, accelerating our experimentation cycle.
- Optimal CPU Selection: The CPU_X64_S instance type within SPCS provided a good balance of CPU power and memory for our LTR model when combined with Ray’s batching, proving that ‘more’ isn’t always ‘better’ for specific workloads if not utilized efficiently.
Google Colab for External Benchmarking
The experiment with the LTR Model in Google Colab + Ngrok on an NVIDIA T4 GPU provided a stark contrast, resulting in a significantly higher latency of 6.2 seconds for 200 users. This outcome, despite using a powerful NVIDIA T4 GPU (known for its inference capabilities), underscores a crucial point:
- Environmental Overhead: Running in a general-purpose environment like Google Colab, even with a strong GPU, introduces considerable overhead (e.g., network latency, containerization layers not optimized for serving, potential resource sharing with other users) that severely impacts real-time inference performance.
- GPU vs. CPU for LTR: While GPUs excel at highly parallelized tasks typical of deep learning, a simpler LTR model, especially one optimized with numpy and served efficiently with Ray’s CPU-focused batching, might not see the same dramatic benefit from a GPU, or the overhead of GPU utilization might negate its advantages if the model isn’t designed to fully saturate the GPU. This suggests that for certain shallow learning models, a well-optimized CPU-based serving strategy can outperform a less optimized GPU deployment.
The Optimized Configuration
Our final, most refined experiment involved the LTR Model in SPCS with Ray & Ngrok (optimized) on 5 core CPU_X64_S. This configuration achieved an impressive 0.170 seconds for 200 users, slightly outperforming the previous non-optimized CPU_X64_S result.
- Optimized Configuration: Performing further fine-tuning of the Ray Serve configuration and using numpy array operation showed incremental improvement validating the iterative nature of performance engineering.
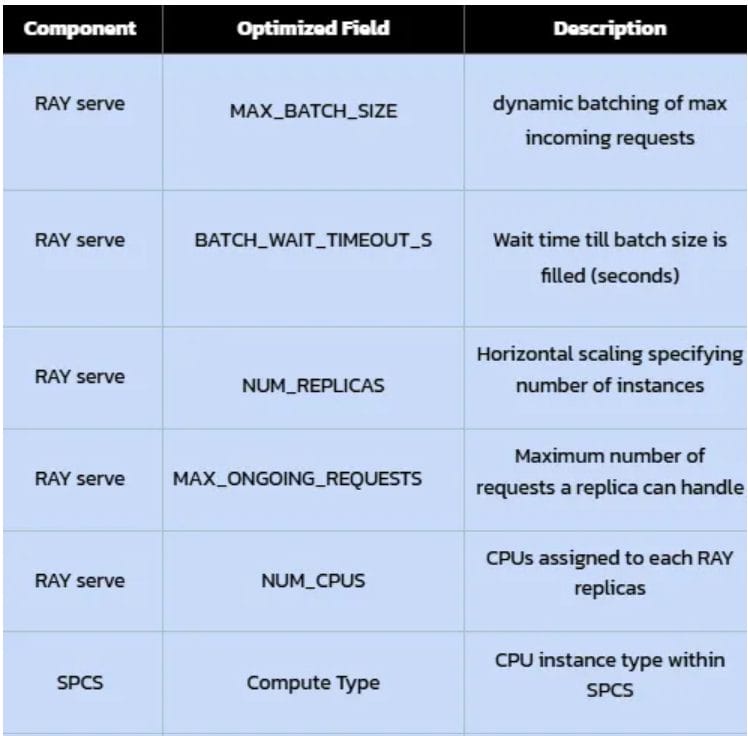
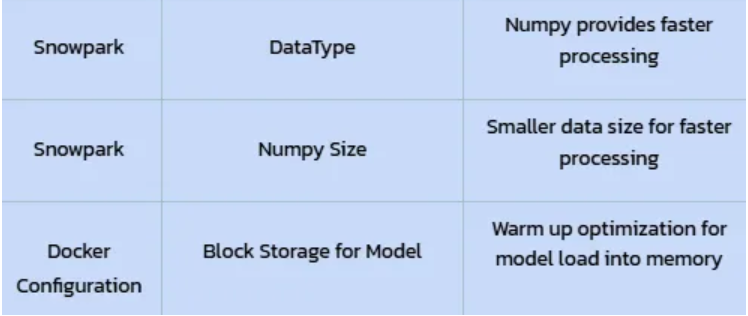
This result represents our optimal balance. We achieved sub-second latency (0.170s), comfortably within our 1-second target, for a significant load of 200 concurrent users. Crucially, this was accomplished on a 5-core CPU_X64_S instance.
Final Verdict: Best Performance vs. Minimal Compute
While changing our recommendation model could result in a slightly altered performance, our experimentation with the LTR model demonstrates that by intelligently combining Snowflake SPCS, Ray Serve’s dynamic batching, and careful model/code optimization, we can achieve:
- Exceptional Latency: Consistently below our 1-second target, ensuring a seamless user experience.
- Scalability: Handling 200 concurrent users with ease.
- Cost Efficiency: Achieving this performance on a modest 5 core CPU_X64_S instance, rather than expensive GPU compute or overly large CPU nodes, which aligns with responsible resource utilization.
Snowflake’s Snowpark Container Services, when paired with the right serving strategies, is a highly capable platform for deploying and scaling real-time machine learning inference, empowering businesses to deliver truly personalized and instantaneous experiences.
References
- Container Runtime For GPU Training & Inference — Use GPU in Snowflake Notebooks
- Deploy Model in SPCS — Quickstart to push a model into SPCS and create a service
- External access for Snowflake Notebooks — Create an external access integration for PyPI
Have questions or want to explore how this solution can work for your organization?
Feel free to reach out to us at info@kipi.ai or follow us on LinkedIn to learn more.
About kipi.ai
Kipi.ai, a WNS Company, is a global leader in data modernization and democratization focused on the Snowflake platform. Headquartered in Houston, Texas, Kipi.ai enables enterprises to unlock the full value of their data through strategy, implementation and managed services across data engineering, AI-powered analytics and data science.
As a Snowflake Elite Partner, Kipi.ai has one of the world’s largest pools of Snowflake-certified talent—over 600 SnowPro certifications—and a portfolio of 250+ proprietary accelerators, applications and AI-driven solutions. These tools enable secure, scalable and actionable data insights across every level of the enterprise. Serving clients across banking and financial services, insurance, healthcare and life sciences, manufacturing, retail and CPG, and hi-tech and professional services, Kipi.ai combines deep domain excellence with AI innovation and human ingenuity to co-create smarter businesses. As a part of WNS, Kipi.ai brings global scale and execution strength to accelerate Snowflake-powered transformation world-wide.
For more information, visit www.kipi.ai.





