
By Manish Kundu and Amit Khandelwal
Introduction
For over a decade, Apache Spark has been the predominant technology used for large-scale data processing, enabling organizations to tackle complex data engineering and machine learning workloads. But its immense power has often come with big trade-offs – architectural and infrastructure complexity and extensive maintenance. Traditional Spark deployments require cluster management, operational overhead for patching, upgrading, monitoring and troubleshooting the clusters, resource inefficiencies, unpredictable costs, data shuffling bottlenecks, memory management and most importantly a steep learning curve for the team managing Spark workloads. This has forced organisations to spend considerable amounts of time and money to build, upgrade and manage these Spark workloads, reducing the time effectively available for new feature developments in their products.
What if you could harness the full power of Apache Spark without ever moving your data or managing complex compute clusters? This is the revolutionary promise delivered by Snowpark Connect for Apache Spark. It fundamentally redefines the relationship between Spark and the Snowflake AI Data Cloud by allowing you to run your existing Spark workloads directly on Snowflake’s platform, processing data where it lives without requiring data movement or separate compute.
How It Works
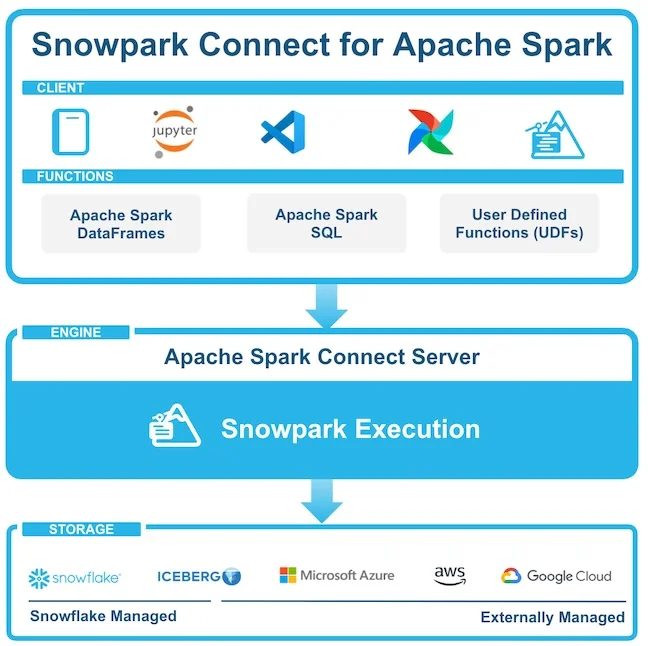
The connector acts as a powerful bridge between the Apache Spark and Snowflake ecosystems. Instead of the traditional “Extract, Transform, Load” (ETL) process where you pull data out of a data warehouse to process it in separate Spark clusters, this model pushes the computational logic down to the data.
Here’s the process:
- Already working with Spark? Your existing PySpark code using DataFrame or SQL APIs runs seamlessly with Snowpark Connect – no rewriting required.
- Snowpark Connect intercepts these Spark API calls.
- It translates them into Snowpark operations, which are native to the Snowflake platform.
- These operations are then executed directly on Snowflake’s elastic compute engines (virtual warehouses), right alongside your data.
This approach effectively turns Snowflake into the execution backend for your Apache Spark jobs.
Key Benefits
This integration offers significant advantages over traditional Spark compute infrastructures.
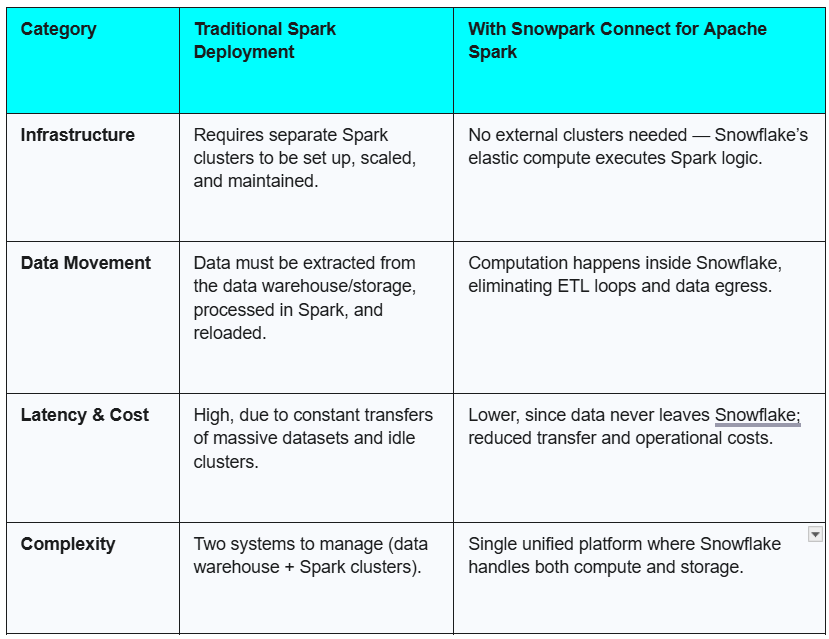
- Eliminates Data Silos & Movement
Since the computation happens inside Snowflake, there’s no need to move massive datasets to an external processing cluster. This reduces latency, lowers data transfer costs, keeps your data secure & governed thereby simplifying your data pipelines overall. - Simplified Architecture
You can eliminate the cost and complexity of setting up, managing, and maintaining separate Spark infrastructure. Snowflake handles all the underlying compute management, scaling, and maintenance. - Leverage Existing Skills
Developers don’t need to learn new languages or frameworks to migrate the code & data. They can continue to use their existing Spark code and expertise while benefiting from a more performant and scalable platform. - Unified Governance and Security
By keeping data and processing within Snowflake’s ecosystem, all operations inherit Snowflake’s robust, centralized security, governance, and access control policies. This ensures data is handled consistently and securely without extra configurations.
Traditional Spark vs. Snowpark Connect for Apache Spark
Conclusion
The Snowpark Connector for Apache Spark is more than a new feature; it represents a strategic evolution in cloud data architecture. By seamlessly merging the world’s most popular distributed processing language paradigm with a leading data cloud platform, Snowflake is empowering organizations to build more efficient, secure, and cost-effective data pipelines. This integration unlocks new potential, allowing businesses to run their most demanding data engineering workloads with unparalleled simplicity and scale.
About kipi.ai
Kipi.ai, a WNS Company, is a global leader in data modernization and democratization focused on the Snowflake platform. Headquartered in Houston, Texas, Kipi.ai enables enterprises to unlock the full value of their data through strategy, implementation and managed services across data engineering, AI-powered analytics and data science.
As a Snowflake Elite Partner, Kipi.ai has one of the world’s largest pools of Snowflake-certified talent—over 1000+ SnowPro certifications—and a portfolio of 250+ proprietary accelerators, applications and AI-driven solutions. These tools enable secure, scalable and actionable data insights across every level of the enterprise. Serving clients across banking and financial services, insurance, healthcare and life sciences, manufacturing, retail and CPG, and hi-tech and professional services, Kipi.ai combines deep domain excellence with AI innovation and human ingenuity to co-create smarter businesses. As a part of WNS, Kipi.ai brings global scale and execution strength to accelerate Snowflake-powered transformation world-wide.
For more information, visit www.kipi.ai.





